Sklearn 中的线性回归模型
线性回归的数学模型
假设单变量回归模型:
$$
h_\theta(x) = \theta^T x = \theta_0 + \theta_1 x_1
$$
这里的 $\theta_0$ 就是偏置,而 $\theta_1$ 就是权重,而 $x_1$ 就是特征。
线性回归方程的代价函数为:
$$
J(\theta) = \frac{1}{2m} \sum^{m}{i = 1}(h_\theta(x^{(i)}) - y^{(i)})^2
$$
这里根据代价函数来计算当前权重与偏置得到的方程与实际情况差距有多大,线性回归问题就是要通过一定方法找到最合适的参数来构造这个方程,也就是找到合适的 $\theta_0$ 和 $\theta_1$ 来使代价函数的值最小,也就是最符合实际情况。
一般来说通过梯度下降的方法来让参数不断接近最优解:
$$
\theta_j:= \theta_j - \alpha \frac{1}{m}\sum^m_{i = 1}(h_\theta(x^{i}) - y^{(i)})x_j^{(i)}
$$
每次跟新都会根据代价函数来更改参数,代价函数在这里反应了与最优解的差距。而式中 $\alpha$ 为学习率,也就是每次更新的幅度。学习率过大会导致下降可能会跳过最优解甚至导致当前值与最优解越来越远,太小会导致循环次数过多靠近最优解的速度太慢。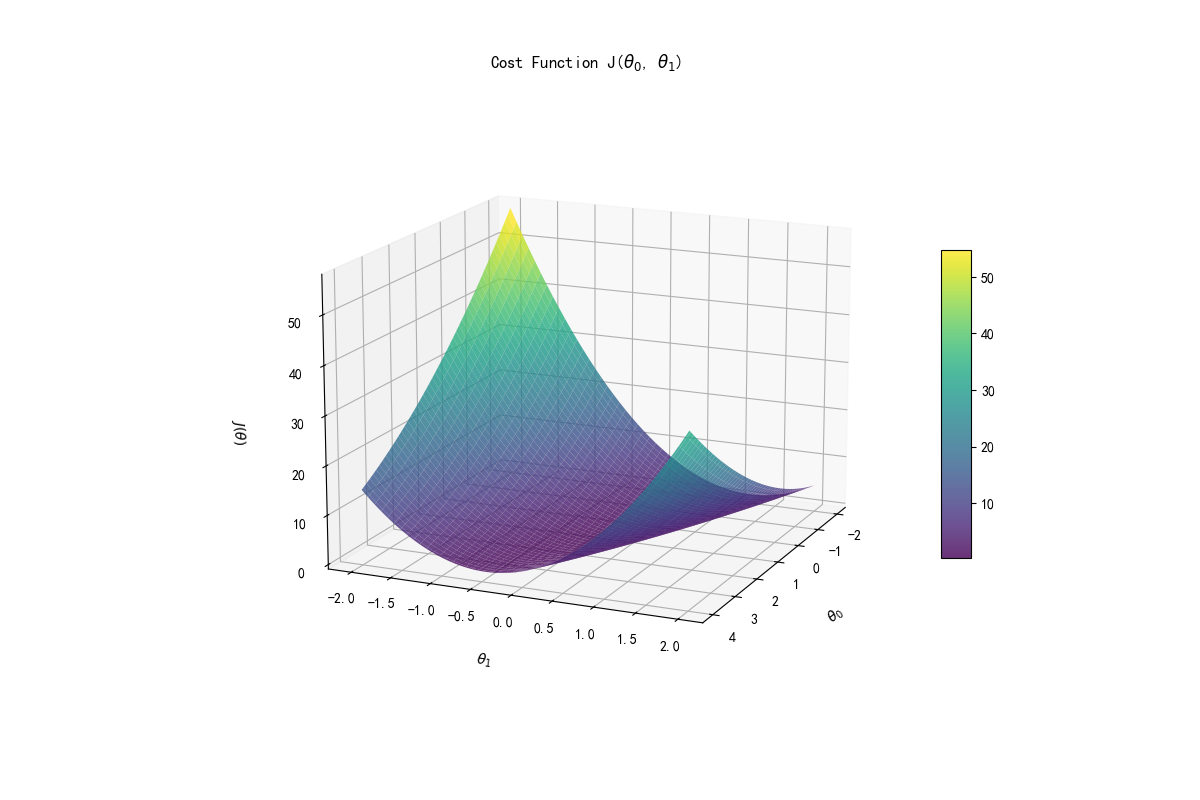
当然,在这里我们使用 python scikit-learn 库来构建线性回归模型,不需要完全读懂数学模型。只需要理解这个模型需要进行什么操作得到最终结果即可。
Sklearn 单变量线性回归
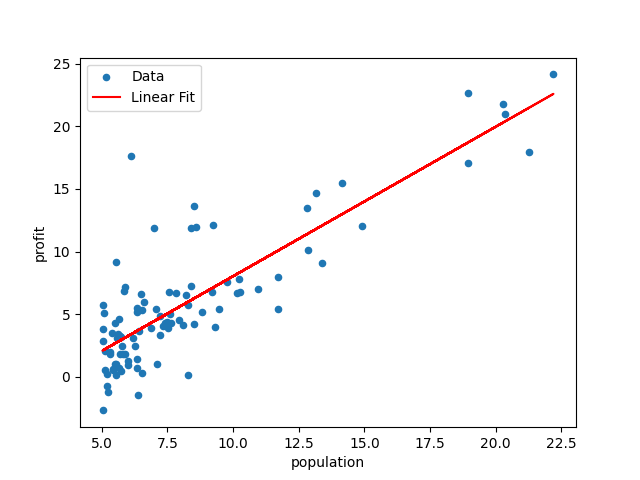
假设有一份食品供应商的数据,包含了城市的人口(population)和在这个城市的利润(profit),需要以人口作为特征来预测在某个城市的利润。
数据处理
假设数据保存在本地的 ex1data1.txt 中并以 csv 文件格式保存,那么需要首先用 pandas 读取数据。
1 | import numpy as np |
查看到数据的头部信息:
1 | population profit |
然后需要将特征和答案传入 Sklearn 线性回归模型,需要注意的是,这里是单变量回归,而一般的线性回归模型接受的参数是一个特征矩阵,那么这里需要将一维的特征向量转换成矩阵形式才行。
1 | X = data['population'].values.reshape(-1, 1) # 重构特征的数据形状 |
构建模型
首先利用构造函数初始化一个线性回归模型对象 model ,然后利用现有的训练数据训练模型。
1 | from sklearn.linear_model import LinearRegression |
验证
从模型中取出最终训练后的参数:
1 | slope = model.coef_[0] |
查看最终的模型:
1 | Linear model equations: y = 1.19x + -3.90 |
通过取出的参数来绘制图形,查看模型的拟合效果是否良好:
1 | import matplotlib.pyplot as plt |
Sklearn 多变量线性回归
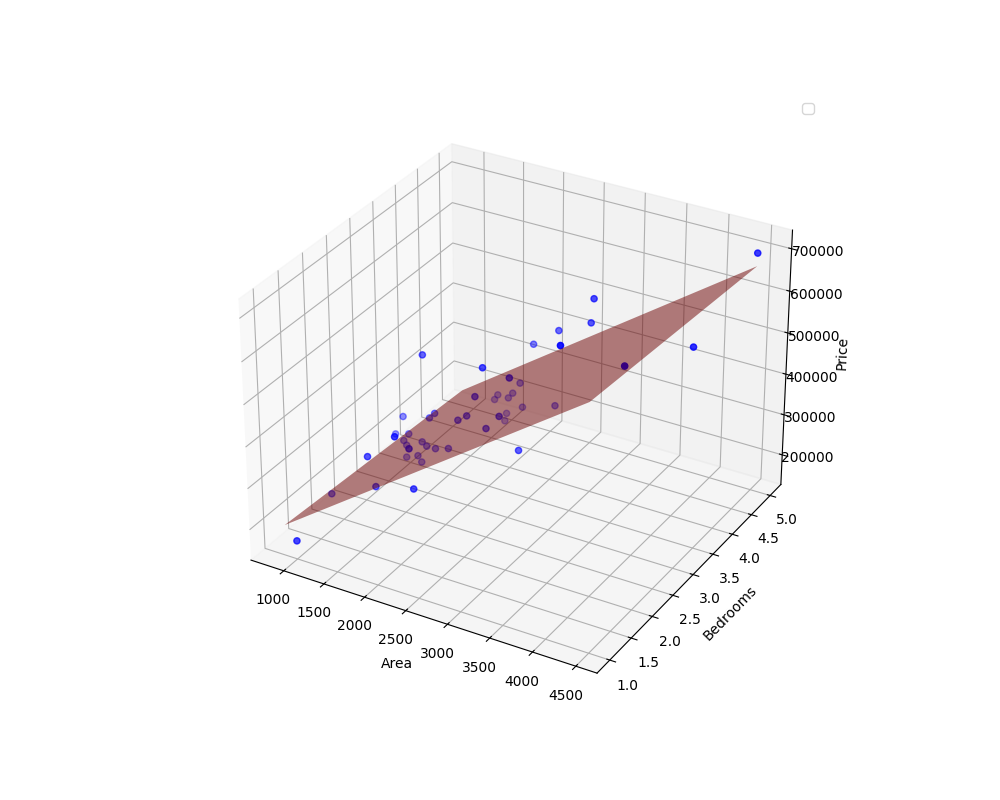
多变量回归模型的构建大同小异,也是一样的步骤。这里假设有数据 ex1data2.txt,数据包含了房屋面积,卧室数量和房屋的价格,以前两者为特征来预测房屋价格。
数据处理与训练
首先读取数据:
1 | data = pd.read_csv('ex1data2.txt', header=None, names=['area', 'bedrooms', 'price']) |
1 | area bedrooms price |
训练模型
1 | X = data[['area', 'bedrooms']].values |
验证
查看训练后的模型的参数:
1 | coefficients = model.coef_ |
1 | Linear model equation: y = 139.21 * area + -8738.02 * bedrooms + 89597.91 |
这里如果需要画图,则需要绘制一个三维图片,因为此处的特征是二维的。
1 | fig = plt.figure(figsize=(10, 8)) |